Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
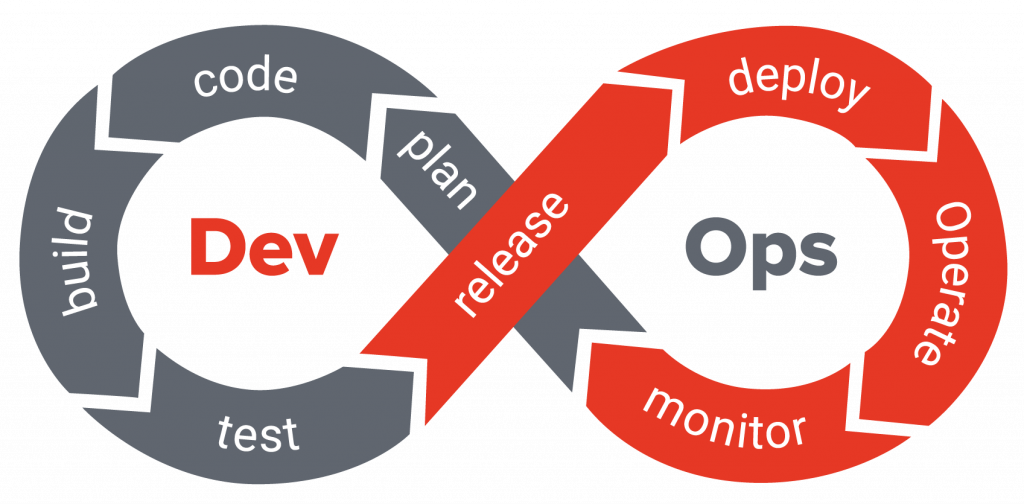
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
 Очная
Очная Дистанционная
Дистанционная Дистанционная: утро
Дистанционная: утро
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная Подтвержден
Подтвержден
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
ПодтвержденКод курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Дистанционная
Подтвержден
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
ПодтвержденКод курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.

Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.

Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
ДистанционнаяКод курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
ПодтвержденКод курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная
Подтвержден
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Код курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
ОчнаяКод курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
ДистанционнаяКод курса.
У каждого курса есть свой уникальный код. Зная этот код вы можете быстро найти курс в форме поиска.
Очная
Дистанционная